 155-6153-2279
155-6153-2279 微信客服
微信客服框分类采集器
阅读:2.43万
评论:21
点赞:18
2019-10-29
框分类采集器.zip(2025/8/6 | 278.57KB | 下载次数:1192)
特点:
1、采集内容自动分部到当天各时间段,不会出现所有信息发布时间都一样的问题,模拟正常发布。
2、不会重复采集,可以自动更新已采集过的信息。
3、自动上传图片,可以增加水印覆盖。
4、支持多网站多任务采集
5、自动过滤网站电话黑名单信息
6、自动识别中介信息,并加标注。
7、过滤非法词。
最新更新版本增加商家、文章、问答采集功能
使用说明:
下载采集器解压,运行程序如图

点击登录用户,输入官网的账号和密码,这里会显示登录成功和采集器到期日期。采集器免费7天,到期后可以直接在官网续费。

登录官网,用户中心,点击续费即可,收费为30元一个月 150元年半 200元一年。

点击采集器的网站管理 - 添加网站
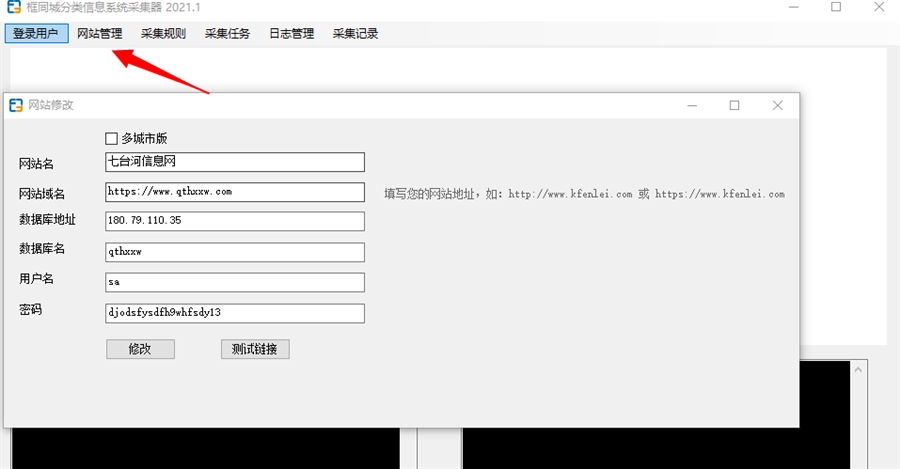
填写网站资料

采集规则 - 载入采集规则,把最新的采集规则载入进来,针对不同网站对应不同的采集规则。站长也可以自己写采集规则,可以看采集器规则教程。
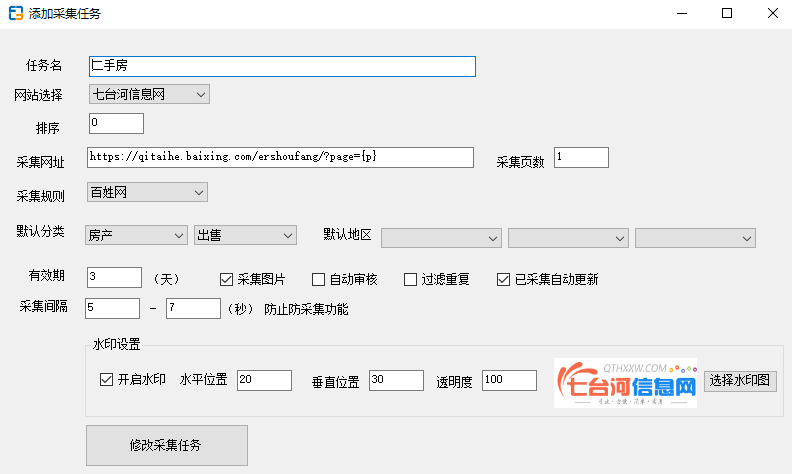
任务名:自己写一个,方便记住
网站选择:选择要把采集的信息写入哪个网站
排序:是采集的顺序,因为可以填加多个任务,所以排序数字越大的,先采集
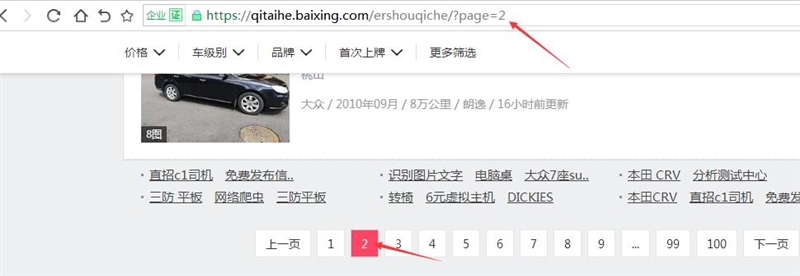
采集网址:直接把要采集网站的信息列表页面地址填上,这里直接填上百姓网二手车的网页地址,把页码替换成{p}
注(百姓网二手车点第二页时,网址中变为2的数字就是页码,把这个2替换成{p}就可以了,其它网站也是照此操作)
采集页数:要采集多少页,是从后页向前采集
采集规则:根据你要采集的网站选择对应的规则,这里要采集百姓网,所以选择百姓网
默认分类:这里会显示你网站的分类,选择你要采集到哪个分类中 (注:如果不选择,采集器会根据内容自动判断)
默认地区:选择采集到哪个地区(注:如果不选择,采集器会根据内容自动判断)
有效期:这里填采集到的信息的有效期
采集图片:钩选就采集图片,不选就不采集
自动审核:钩选就是采集到的信息自动审核,不钩选就是要手动去后台审核
采集任务都添加好后,点击开始采集,等待采集完成
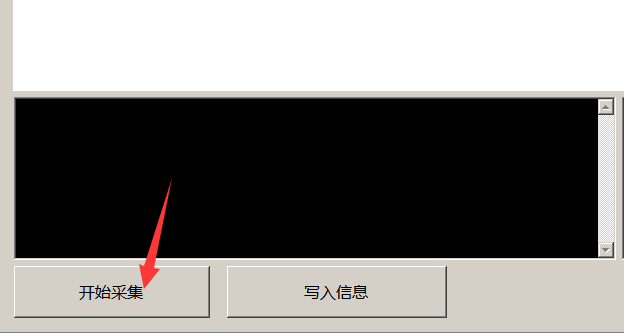
采集完成后,可以看到提示,采集完成,请点击写入信息。右侧显示每个任务采集成功多少条信息,重复多少条,黑名单多少条,失败多少条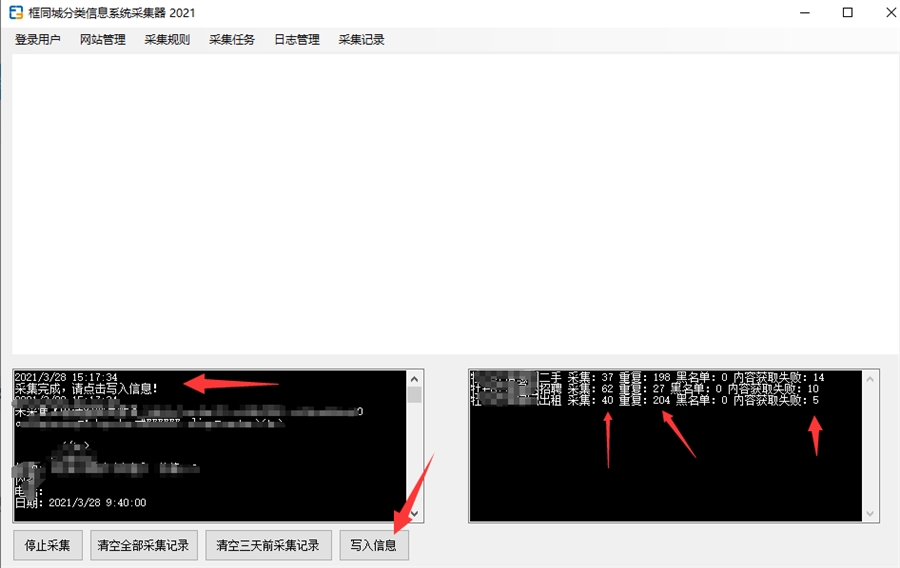
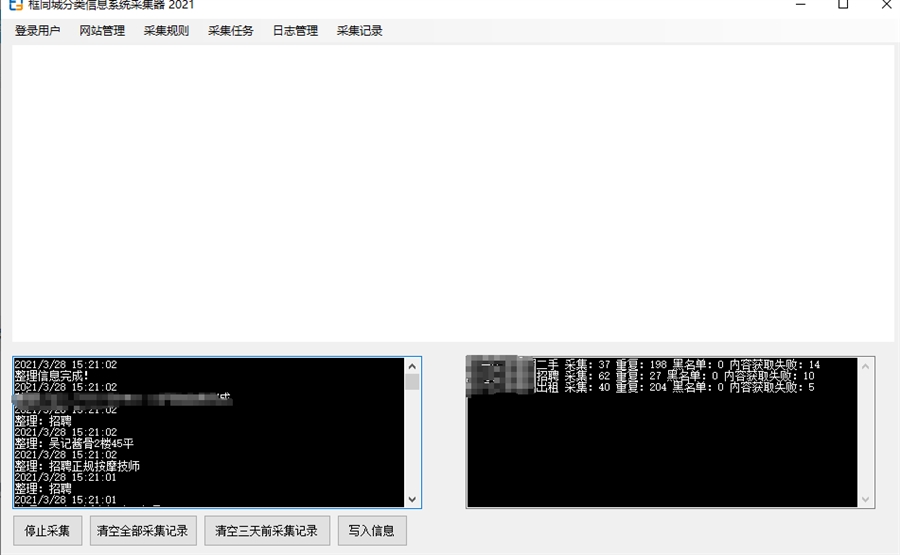
这个采集器采集的信息是自动分部到当天凌晨5点到当前时间段的,所以不会出现所有信息发布时间都一样的问题
采集器采集过的信息是不会重复采集的,如果想重新采集已经采集过的内容,可以点一下清空全部采集记录或清空三天前采集记录
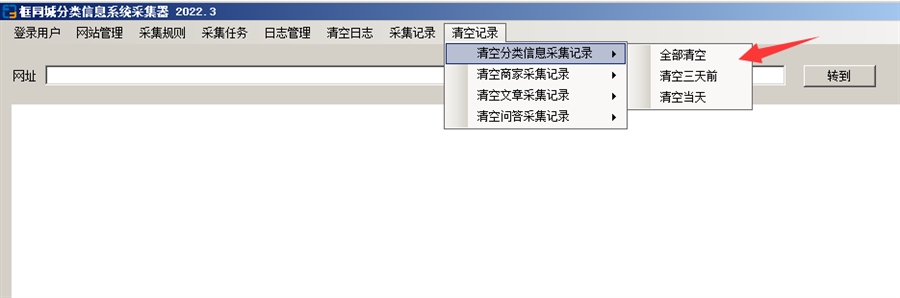
采集器用了一段时间后,如果目录太大,可以点一下 清空三天前采集记录 ,这样会把三天前的采集记录清空
使用说明:
下载采集器解压,运行程序如图
点击登录用户,输入官网的账号和密码,这里会显示登录成功和采集器到期日期。采集器免费7天,到期后可以直接在官网续费。
登录官网,用户中心,点击续费即可,收费为30元一个月 150元年半 200元一年。
点击采集器的网站管理 - 添加网站
填写网站资料
注:如果你的程序是多城市版,把多城市版钩选上
域名直接填你网站的域名,这个域名是用来把采集到的图片上传到你的网站上的
数据库地址一般就是你的服务器IP
域名直接填你网站的域名,这个域名是用来把采集到的图片上传到你的网站上的
数据库地址一般就是你的服务器IP
使用官网合租服务器的,数据库地址是域名解析地址加,2988
如:hosts3.ktongcheng.com,2988 注:逗号要用英文状态下的
数据库名、用户名、密码,可以在你的网站的web.config文件中找到,如图

database=后面的是数据库名
uid=后面的是数据库用户名
pwd=后面的是数据库密码
都填好后点一下测试数据库链接,提示链接成功为正常,本采集器可以同时为多个网站采集内容,所以可以添加多个网站资料。
添加好网站后,点一下网站管理中的【更新载入网站配置】,将网站的信息分类、地区分类、电话黑名单、中介电话名单、过滤词导入过来。
database=后面的是数据库名
uid=后面的是数据库用户名
pwd=后面的是数据库密码
都填好后点一下测试数据库链接,提示链接成功为正常,本采集器可以同时为多个网站采集内容,所以可以添加多个网站资料。
添加好网站后,点一下网站管理中的【更新载入网站配置】,将网站的信息分类、地区分类、电话黑名单、中介电话名单、过滤词导入过来。
当网站的分类、地区和电话黑名单等有变动时,重新点一下。
采集器不会采集电话黑名单的信息
采集器不会采集电话黑名单的信息
采集规则 - 载入采集规则,把最新的采集规则载入进来,针对不同网站对应不同的采集规则。站长也可以自己写采集规则,可以看采集器规则教程。

添加采集任务,以采集百姓网二手车为例。
点击采集任务 - 添加任务
点击采集任务 - 添加任务
任务名:自己写一个,方便记住
网站选择:选择要把采集的信息写入哪个网站
排序:是采集的顺序,因为可以填加多个任务,所以排序数字越大的,先采集
采集网址:直接把要采集网站的信息列表页面地址填上,这里直接填上百姓网二手车的网页地址,把页码替换成{p}
注(百姓网二手车点第二页时,网址中变为2的数字就是页码,把这个2替换成{p}就可以了,其它网站也是照此操作)
采集页数:要采集多少页,是从后页向前采集
采集规则:根据你要采集的网站选择对应的规则,这里要采集百姓网,所以选择百姓网
默认分类:这里会显示你网站的分类,选择你要采集到哪个分类中 (注:如果不选择,采集器会根据内容自动判断)
默认地区:选择采集到哪个地区(注:如果不选择,采集器会根据内容自动判断)
有效期:这里填采集到的信息的有效期
采集图片:钩选就采集图片,不选就不采集
自动审核:钩选就是采集到的信息自动审核,不钩选就是要手动去后台审核
过滤重复:当有两条信息内容是一样时,只采集一条,因为有的网站有大量重复信息
已采集自动更新:之前采集过的信息,会直接更新,不会重复采集(不钩选,不会采集之前采集过的信息,也不会更新)
采集间隔:有的网站有防采集功能,访问速度太快会被屏蔽,这里可以把采集间隔设置3到5秒
水印设置,可以用来遮挡采集图片上的水印,可以自己设置水印位置和透明度,100为不透明,0为完全透明。
都填好后,点添加采集任务
在采集管理 - 任务管理中,可以看到所有的采集任务,可以修改和删除,如果临时不想采集某个任务,可以把任务前的钩去掉
在采集管理 - 任务管理中,可以看到所有的采集任务,可以修改和删除,如果临时不想采集某个任务,可以把任务前的钩去掉
采集任务都添加好后,点击开始采集,等待采集完成
采集完成后,可以看到提示,采集完成,请点击写入信息。右侧显示每个任务采集成功多少条信息,重复多少条,黑名单多少条,失败多少条
点写入信息,这样就把采集到的信息和图片上传到网站中了
等待写入和整理完成,就可以关闭采集器了
这个采集器采集的信息是自动分部到当天凌晨5点到当前时间段的,所以不会出现所有信息发布时间都一样的问题
采集器采集过的信息是不会重复采集的,如果想重新采集已经采集过的内容,可以点一下清空全部采集记录或清空三天前采集记录
采集器用了一段时间后,如果目录太大,可以点一下 清空三天前采集记录 ,这样会把三天前的采集记录清空
upload中保存的是采集到的图片,已经上传了的,会直接删除,这里可能有一些没有删除成功的,可以定期自己手动删除一下

采集器常见问题及处理方法
一些采集规则是模拟浏览器访问进行采集的,需要IE浏览器能正常访问网站。
如果采集的过程中显示如下图,此网站的安全证书存在问题

或如下图,无法打开页面
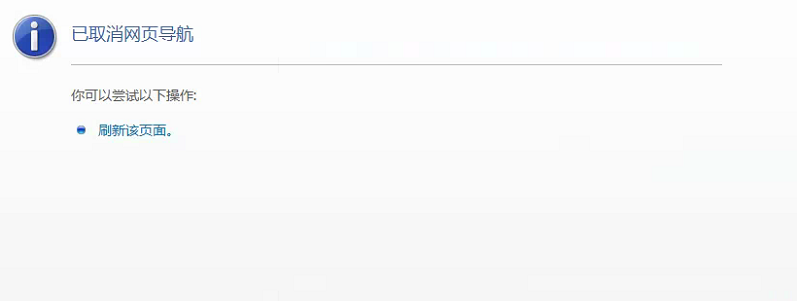
请打开你的IE浏览器,点击设置 - internet选项

将使用SSL3.0、使用TLS 1.0、使用TLS 1.1、使用TLS 1.2、使用TLS 1.3 都钩选上,点击确定,重启电脑就可以解决。
在采集百姓网的过程中,如果采集间隔设置太短容易被屏蔽,建议采集间隔设置为5-10秒



 黑公网安备 23090402000014号
黑公网安备 23090402000014号